Skriv så AI-modellerne ikke kan ignorere dig
Google gætter ikke længere. I dag skal du levere tekniske beviser for din eksistens, din ekspertise og din branche. Her er metoderne til at overleve skiftet til AI-søgning.
Det nye SEO-landskab
Brugeradfærden og søgeteknologi ændre sig lige nu. Ifølge markedsdata (bl.a. SparkToro, 2024) resulterer ca. 60% af alle søgninger i dag i “Zero-Click”. Det betyder, at brugeren finder svaret direkte på Google eller via en AI-assistent som ChatGPT eller Perplexity uden nogensinde at besøge kildehjemmesiden. Samtidig estimerer Gartner (2024), at udbredelsen af GenAI vil reducere traditionel søgetrafik med 25% inden 2026.
For mig at se skifter den primære målsætning fra trafikgenerering til Brand Authority, hvor målet er at blive den primære kilde for AI-genererede svar. Hvis du ikke er den citerede kilde, eksisterer du ikke i brugerens bevidsthed.
Indhold på denne side
Særligt kritisk for YMYL-virksomheder (Your Money or Your Life)
Selvom E-E-A-T er relevant for alle, er det for visse brancher direkte afgørende. Google opererer med et begreb kaldet YMYL, hvilket dækker over webindhold, der kan have en direkte indvirkning på brugerens sundhed, økonomi, sikkerhed eller trivsel. Det gælder for eksempel banker, advokater, privathospitaler og socialpædagogiske botilbud.
Fejlinformation på disse områder kan være direkte skadelig for brugeren. Derfor prioriterer Google benhårdt, at indhold relateret til YMYL udelukkende kommer fra erfarne eksperter med høj autoritet. Har du en virksomhed i denne kategori, er det ikke nok, at dine informationer er korrekte. De skal præsenteres af verificerbare fageksperter for at rangere i søgeresultaterne.
Det store skifte: Fra søgeord til entiteter
Skiftet fra streng-baseret søgning (keywords) til koncept-baseret søgning (entiteter) kræver en ny teknisk tilgang til synlighed.
- Gammel SEO: Google scannede tekst og brugte komplekse formler til at gætte, hvad din virksomhed lavede, baseret på hvor mange gange du skrev “billig VVS”.
- Ny SEO (Entitets-baseret): Moderne søgemaskiner og LLM’er (Large Language Models) tænker i “entiteter” – det vil sige personer, virksomheder og koncepter, der er unikt definerede i en Knowledge Graph (vidensgraf).
Hvis Google ikke forstår, at din virksomhed er en unik entitet med specifikke attributter (lokation, branche, ydelser), bliver du usynlig. Du kan ikke længere håbe på, at algoritmen gætter rigtigt. Du skal føde maskinerne med fakta.
Fakta: Dette kendetegner en Entitet
I moderne SEO defineres en entitet bedst som: “Ting, ikke tekststrenge”.
Hvor Google tidligere blot matchede dine søgeord (strings) 1:1 med tekst på en hjemmeside, forstår søgemaskinen i dag betydningen bag ordene. En entitet er en unik, definerbar størrelse – det kan være en person, et sted, et produkt eller et koncept – som Google kan kende forskel på gennem sin Knowledge Graph.
Eksempel:
- Søgeord: Ordet “Amazon” er blot 6 bogstaver. Er det floden eller webshoppen?
- Entitet: Google forstår konceptet Amazon (virksomheden) via dens relationer til andre entiteter (Jeff Bezos, e-handel, Prime Video).
Når vi taler om en “ny teknisk tilgang”, betyder det, at vi ikke længere bare skal optimere tekst, men aktivt hjælpe Google med at forstå disse relationer gennem struktureret data og semantisk sammenhæng.
Hvorfor AI-genereret indhold mangler indbygget Google E-E-A-T
Med den stigende brug af sprogmodeller er det vigtigt at forstå forskellen på maskinel viden og menneskelig ekspertise. AI-systemer kan analysere og opsummere enorme datasæt på sekunder. Det giver dem en form for overfladisk erfaring.
Men en AI mangler den intuitive forståelse, den etiske overvejelse og den dybe indsigt, der kommer fra reel, praktisk erfaring. Den kan generere tekst baseret på data, men den mangler den nuancerede, subjektive vurdering, som en fagekspert bringer til bordet. Samtidig har maskiner ikke autoritet i traditionel forstand, da de ikke har formelle uddannelser eller et professionelt ry. Det betyder, at rent AI-genereret indhold ofte vil mangle den dybde og troværdighed, som Google leder efter. Det er helt acceptabelt at bruge AI som et skriveværktøj, men indholdet skal altid kvalitetsstemples af en menneskelig ekspert for at opnå E-E-A-T.
Sådan dokumenterer du troværdighed (Det tekniske fundament)
Troværdighed er ikke længere bare en følelse eller et godt design. Det er data. For at opnå høj E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) skal du implementere specifikke tekniske signaler, der validerer både din forretning og dig selv, over for maskinerne/LLM’s.
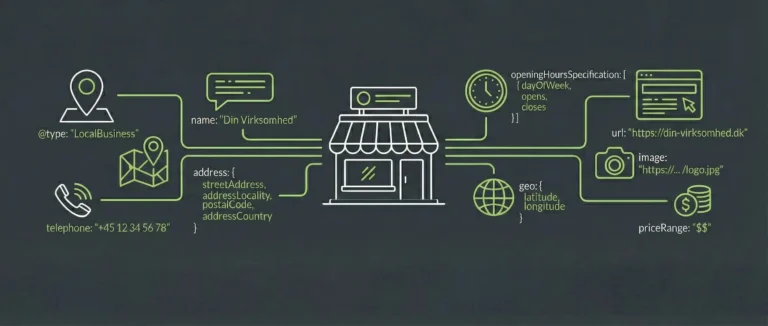
Schema Data: Tag kontrollen over jeres data
For at AI og søgemaskiner kan forstå din forretning korrekt, skal du tale deres sprog – JSON-LD. Uden Schema gætter Google sig til dine attributter.
Med Schema dikterer du fakta. Det sikrer præcis indeksering og hjælper AI-modeller med at skelne jeres brand fra konkurrenternes.
Brug følgende datatyper for at låse jeres entiteter fast:
- E – Experience (Erfaring): Dette dækker over førstehåndserfaring. Sprogmodeller kan opsummere eksisterende viden, men de har aldrig testet et produkt i virkeligheden eller løst et problem for en fysisk kunde. Du skal bevise, at du har praktisk erfaring med det, du skriver om.
Praktisk implementering: Brug Schema-typen “Review” eller “Product” til at fremhæve kundeanmeldelser og resultater fra dine egne tests. Det markerer over for søgemaskinerne, at dit indhold bygger på reelle, fysiske interaktioner med produktet eller ydelsen, og ikke bare er omskrevet teori. - E – Expertise (Ekspertise): Her handler det om den formelle faglige viden bag teksten. Har forfatteren den nødvendige uddannelse, stilling eller baggrund til kvalificeret at udtale sig om emnet?
Praktisk implementering: Tilføj “Person” eller “Author”-schema på dine forfatterprofiler eller artikler. Med denne data kan du fodre maskinerne med specifikke oplysninger om forfatterens uddannelse, jobtitel og faglige baggrund. Sørg for at linke denne person-entitet direkte til en LinkedIn-profil eller en dedikeret forfatterside på dit website, så der ikke er nogen tvivl om afsenderens faglige historik og niveau. - A – Authoritativeness (Autoritet): Autoritet handler om dit omdømme og din position i branchen. Er du den kilde, andre eksperter og medier henviser til, når de skal bruge præcis information?
Praktisk implementering: Brug attributten “sameAs” i din Schema-markering. Mange linker blot til deres LinkedIn-profil i selve den synlige tekst, men den forbindelse er ikke automatisk teknisk synlig for søgemaskinerne. Ved at lægge linket direkte ind i din Schema-data via sameAs-tags, kobler du din sociale tilstedeværelse samt dine officielle, eksterne registreringer (som f.eks. CVR-registret, Facebook eller Wikipedia) entydigt sammen med dit domæne. Det er et afgørende greb til at opbygge din autoritet i Googles øjne og skabe et solidt, digitalt bevisnetværk, som maskinerne kan placere i deres Knowledge Graph. - T – Trustworthiness (Troværdighed): Troværdighed er selve fundamentet under de tre andre faktorer. Det handler om gennemsigtighed, sikkerhed, og at dine data er faktuelt korrekte og lette at verificere.
Praktisk implementering: Implementer “Organization” eller “Local Business”-schema, typisk på din forside eller kontaktside. Her definerer du virksomhedens juridiske stamdata, officielle navn, CVR-nummer, fysiske adresse og kontaktinformationer. Hvis I har specifikke nøglepersoner tilknyttet vigtige funktioner, kan disse markeres som officielle kontaktpunkter (ContactPoint) med direkte telefonnummer og e-mail. Det fortæller algoritmen præcis, hvem der kan kontaktes, fjerner enhver tvivl om jeres organisatoriske struktur og beviser jeres reelle eksistens.
Ydelser og Markedsområde (Service Schema): Foruden selve E-E-A-T strukturen, bør du eksplicit definere din virksomheds ydelser.
Praktisk implementering: Definer dine specifikke services med et dedikeret “Service”-schema. Her er det afgørende at angive attributten “areaServed”. Google og AI-modeller skal ikke tvinges til at gætte dit markedsområde ud fra teksten; du skal kode det direkte ind, så maskinerne ved nøjagtig, hvilke geografiske byer og regioner du dækker.
Hvordan Google vurderer din indsats i praksis?
Google anvender rigtige mennesker, kendt som Search Quality Raters, til at evaluere kvaliteten af søgeresultaterne ud fra deres retningslinjer. Selvom disse personers vurderinger ikke påvirker algoritmen direkte, bruges deres data til at træne og justere Googles systemer.
En side får en lav score, hvis forfatteren mangler dokumenteret erfaring, hvis indholdet fremstår overfladisk, eller hvis websitet har et negativt omdømme uden tilstrækkelig kundeservice. Omvendt opnår en side en høj score, når den demonstrerer specialiseret viden, underbygges af reelle anmeldelser og fungerer som branchens foretrukne opslagsværk for et specifikt emne.
Konkrete trin til at opbygge digital autoritet
For at understøtte det tekniske arbejde med Schema bør du også implementere nedenstående metoder direkte i dit indhold. Opbygningen af digital autoritet kræver nemlig, at din ekspertise konsekvent underbygges af konkret dokumentation på selve siden:
Tekstforfatning: Skriv for at blive citeret
Når du producerer indhold, skal du tænke ud over blot at dække et emne. AI-modeller leder efter “Information Gain” – altså ny viden, der ikke bare er en gentagelse af de 10 øverste søgeresultater. For at din tekst bliver valgt som kilden (citeret), skal du ændre måden, du opbygger dine sætninger og afsnit på:
- Answer-First Arkitektur (Det omvendte pyramideprincip): Skriv konklusionen først. Start dine afsnit med det konkrete svar inden for de første 40-60 ord. AI-modeller “skimmer” toppen af tekstblokke for fakta. Hvis du gemmer svaret eller pointen til sidst i teksten (som i en roman), risikerer du, at AI’en overser det og vælger en anden kilde.
- Integrer Unikke Data: Gør din tekst uundværlig ved at inkludere proprietære data, egne undersøgelser eller unik statistik. AI elsker at citere hårde tal, der kan verificeres. Hvis din tekst kun indeholder holdninger uden data, har den lav “citerbarhed”.
Webtilgængelighed styrker både læsbarhed og SEO og AI
Webtilgængelighed handler grundlæggende om at sikre, at alle mennesker – uanset funktionsevne – kan bruge dit website. Men der er en stor sidegevinst: De samme strukturer, der hjælper en person med nedsat syn til at forstå din side (via en skærmlæser), er præcis de samme, som Google og AI-modeller bruger til at indeksere dit indhold. Når du bygger inkluderende for mennesker, gør du samtidig dit indhold ekstremt letlæseligt for maskinerne.
- llms.txt: Dette er en ny standard, der fungerer som et “menukort” til AI-robotter. Ved at placere en
llms.txt-fil på dit domæne, giver du AI-agenter (som ChatGPT) en kurateret liste over dine vigtigste sider i et rent format (Markdown), fri for støj. Det sikrer, at de læser dine priser og vilkår korrekt, i stedet for at hallucinere dem. - Webtilgængelighed og CWV: Udover strukturen signalerer en side, der er teknisk tilgængelig og hurtig (Core Web Vitals), omsorg og professionalisme. Dette er en direkte proxy for “Trustworthiness” i Googles øjne, hvilket øger din samlede troværdighed i søgeresultaterne.
Her får du den fulde opskrift på, hvordan du opbygge og bevise din menneskelige ekspertise? Læs min dybdegående guide til Google E-E-A-T her.
Det handler ikke om at gøre arbejdet for AI’en, men om at sikre, at den vælger dig som sandheden.
Chrilles Wybrandt
Det store paradoks: Hvorfor skære det ud i pap for en genial AI?
Man kan undre sig over, at vi skal bruge energi på at håndfodre avancerede AI-systemer med skemadata. Hvis teknologien er så klog, burde den så ikke selv kunne regne det ud?
Udfordringen med det voksende datagrundlag
Problemerne “derude” er mangfoldige:
- Der findes enorme mængder forældede og forkerte informationer, som skal sorteres væk.
- Mængden af data vokser så voldsomt hver eneste dag, at det kræver stadigt flere ressourcer overhovedet at indeksere indholdet.
- Brugerne stiller større krav end nogensinde før. AI kommer typisk kun med ét enkelt svar, og det er helt afgørende, at dette svar er korrekt. Ellers mister du som afsender troværdighed – og i sidste ende kunder.
Elite-data vs. den grå masse
Uden en eller anden form for validering af kilderne til indholdet på nettet, bliver internettet bare én stor, grå masse af data, som AI og Google skal forsøge at fiske meningsfulde svar ud af. Google og AI kan nå langt, men det er også her, den menneskelige faktor fortsat kan gøre en forskel. AI vil naturligvis hellere fodres med “elite-data” – information, der er verificeret af rigtige mennesker.
Tag ejerskab over din fortælling
Når vi bruger teknisk dokumentation til at validere vores identitet, fjerner vi gætterierne.
Vi løfter vores data ud af den grå masse og skaber “øer af sandhed”. Det handler ikke om at hjælpe teknologien for teknologiens skyld. Det handler om, at hvis du ikke selv leverer de verificerede fakta, er AI’en tvunget til at gætte baseret på gennemsnittet af internettet. Og at overlade sit omdømme til et maskinelt gæt er at overlade sin forretning til tilfældighederne.
Ordforklaring (*)
- GEO (Generative Engine Optimization): Processen med at optimere indhold, så det rangerer højt og bliver citeret i svar fra generative AI-søgemaskiner (som ChatGPT Search, Google AI Overviews).
- SEO (Search Engine Optimization): Den klassiske disciplin med at optimere websider for at opnå højere placeringer i traditionelle søgemaskineresultater.
- LLM (Large Language Model): En avanceret AI-model trænet på enorme mængder tekst, der kan forstå og generere menneskelignende sprog (f.eks. GPT-4, Gemini, Claude).
- RAG (Retrieval-Augmented Generation): En teknik, hvor en AI-model henter (retriever) opdateret information fra eksterne kilder (f.eks. dit website) for at generere et præcist svar, fremfor kun at bruge sin indlærte viden.
- Entiteter: Unikke, definerbare objekter eller koncepter (personer, steder, ting, idéer), som en søgemaskine kan identificere og skelne fra andre (f.eks. forskellen på “Apple” frugten og “Apple” virksomheden).
- Knowledge Graph: En database, der strukturerer information som et netværk af entiteter og deres indbyrdes relationer, hvilket giver maskiner en “forståelse” af verden.
- EEAT (Experience, Expertise, Authoritativeness, Trustworthiness): Googles kvalitetskriterier for indhold. Afgørende for, om både algoritmer og mennesker stoler på informationen.
- Topic Clusters: En metode til at organisere indhold, hvor en hovedside dækker et bredt emne, og underliggende sider dækker specifikke detaljer, alt sammen internt linket for at vise ekspertise.
- RAG-citation: Når en AI-model bruger dit indhold til at konstruere et svar og angiver dig som kilden (f.eks. med en fodnote eller et link).